Ibrahim Gabol
Blog
Projects
About
2024
What is Linux?
Jan 8, 2024
2023
LLM chatbots in critical systems
Oct 1, 2023
2022
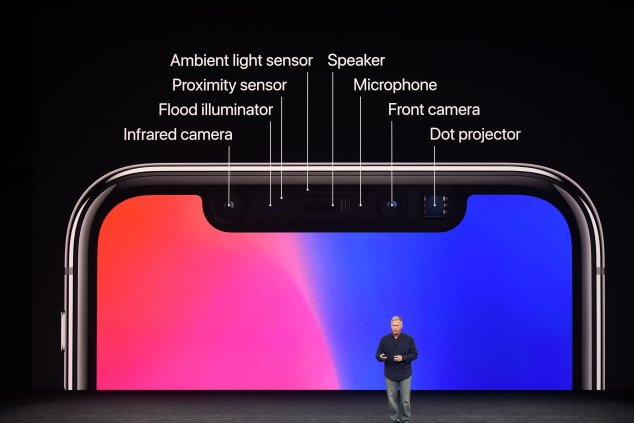
Apple's Face ID, how does it work, and is it safe?
Feb 25, 2022
2021
Driverless cars, good or bad?
Dec 1, 2021